Les IA locals sont sous-cotés

Le 18 juillet 2025 à 23:37:28 :
Ça existe un modèle pas trop gourmand qui tourne sur un PC bureautique?
Phi4

Le 18 juillet 2025 à 23:36:54 [Arkhor] a écrit :
Le 18 juillet 2025 à 23:35:36 WindBox a écrit :
Le 18 juillet 2025 à 23:32:43 [Arkhor] a écrit :
Le 18 juillet 2025 à 23:27:22 WindBox a écrit :
Le 18 juillet 2025 à 23:22:28 [Arkhor] a écrit :
> Le 18 juillet 2025 à 23:19:10 WindBox a écrit :
> > Le 18 juillet 2025 à 21:04:16 [Arkhor] a écrit :
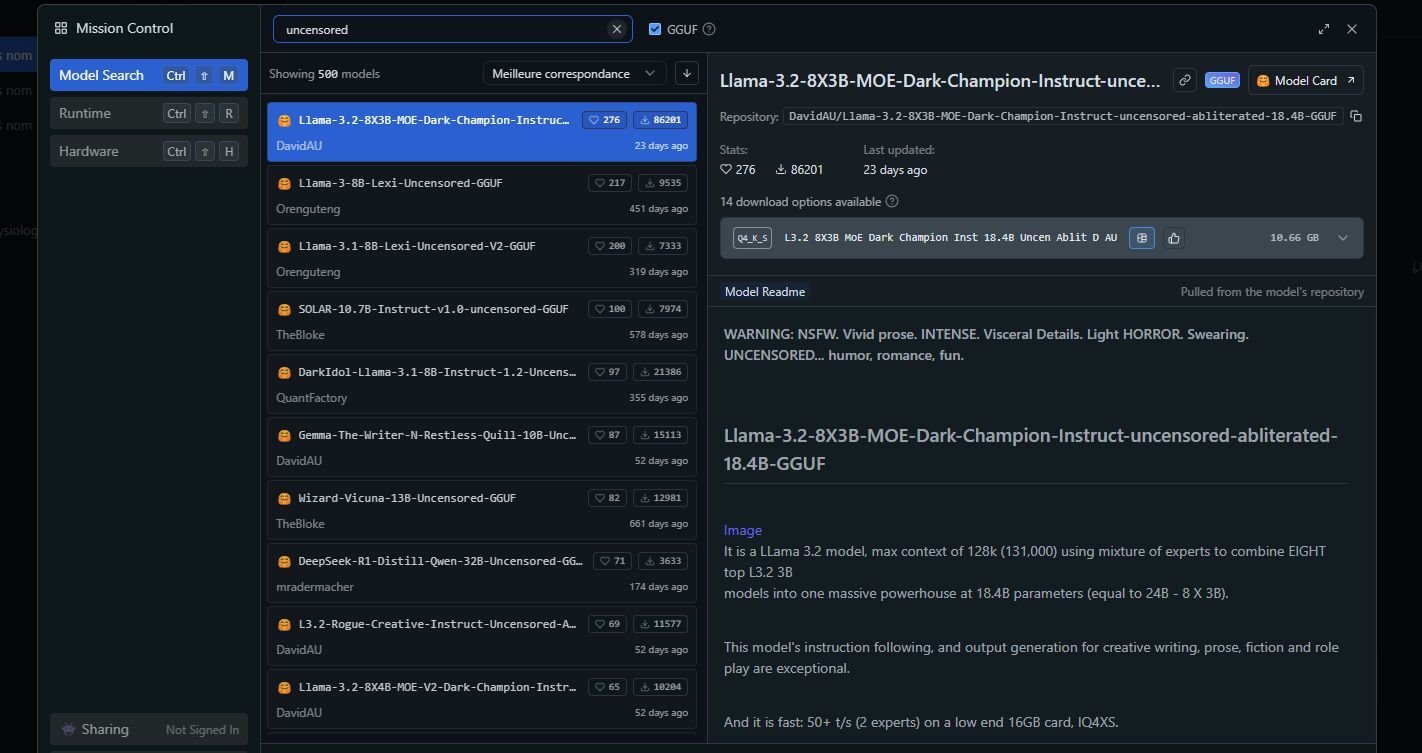
> > Savez vous si on peu télécharger individuellement ces models d'IA ici : https://ollama.com/search?q=uncensored
> > et les intégrés a LM studio, un connurent plus intuitif et accessible que Ollama pour lancer des IA en local ?
>
> Ouais c'est mieux d'ailleurs
> Va dans my models et cherche uncensored et telecharge
>
> Les IA dans LM Studio c'est les mêmes qu'Ollama
ha ok superbe ! gros merci !
Car je te cache pas que ça me gonflé de devoir lancer l'invite de commande windows avec Ollama comme sur MS dos dans les années 80
J'avoue c'est pas ouf la version sur cmd

C'est mieux lm studio
le pire c'est que tu install l'exe Ollama sur windows, a la fin, t'a une icône proche de l'horloge windows, le logiciel est lancé... mais plus d'infos... tu sais plus quoi faire... j'ai du voir sur google qu'il faut aller sur la commande CMD windows.... c'est des pros linux qui on fait le minimum syndicale ça !
Encore merci pour ce beau topic, c'est nettement mieux d'avoir une IA autonome sans connexion au netj'ai télécharger deepseek 2.5 pour 145 go, mais le temps de fou pour le charger. je verrais ça demain.

145GO ???
Mais attend ta combien de VRAM sur ton PC ?vram ? j'ai 8 go de ram de carte vidéo et 32 go de ram classique. j'ai un pc portable avec un ryzen 7 comme GPU et une RTX 4060.





Laisse tomber pélo c'est beaucoup trop gros pour ta config, ça va être inutilisable
Ton PC va devoir swapper et niquer ton SSD en plus d'être EXTREMEMENTISSIMEMENT lent

![Avatar de [Arkhor]](https://image.jeuxvideo.com/avatar-sm/0/a/arkhor_-1748104661-10ed23f02752b160dc7fe610b445df3d.jpg)
Le 19 juillet 2025 à 00:50:32 Cambroussard a écrit :
Le 18 juillet 2025 à 23:36:54 [Arkhor] a écrit :
Le 18 juillet 2025 à 23:35:36 WindBox a écrit :
Le 18 juillet 2025 à 23:32:43 [Arkhor] a écrit :
Le 18 juillet 2025 à 23:27:22 WindBox a écrit :
> Le 18 juillet 2025 à 23:22:28 [Arkhor] a écrit :
> > Le 18 juillet 2025 à 23:19:10 WindBox a écrit :
> > > Le 18 juillet 2025 à 21:04:16 [Arkhor] a écrit :
> > > Savez vous si on peu télécharger individuellement ces models d'IA ici : https://ollama.com/search?q=uncensored
> > > et les intégrés a LM studio, un connurent plus intuitif et accessible que Ollama pour lancer des IA en local ?
> >
> > Ouais c'est mieux d'ailleurs
> > Va dans my models et cherche uncensored et telecharge
> >
> > Les IA dans LM Studio c'est les mêmes qu'Ollama
>
> ha ok superbe ! gros merci !
> Car je te cache pas que ça me gonflé de devoir lancer l'invite de commande windows avec Ollama comme sur MS dos dans les années 80
J'avoue c'est pas ouf la version sur cmd
C'est mieux lm studio
le pire c'est que tu install l'exe Ollama sur windows, a la fin, t'a une icône proche de l'horloge windows, le logiciel est lancé... mais plus d'infos... tu sais plus quoi faire... j'ai du voir sur google qu'il faut aller sur la commande CMD windows.... c'est des pros linux qui on fait le minimum syndicale ça !
Encore merci pour ce beau topic, c'est nettement mieux d'avoir une IA autonome sans connexion au net145GO ???
Mais attend ta combien de VRAM sur ton PC ?vram ? j'ai 8 go de ram de carte vidéo et 32 go de ram classique. j'ai un pc portable avec un ryzen 7 comme GPU et une RTX 4060.
Laisse tomber pélo c'est beaucoup trop gros pour ta config, ça va être inutilisable
Ton PC va devoir swapper et niquer ton SSD en plus d'être EXTREMEMENTISSIMEMENT lent
ok je m'avoue vaincu, merci, je vais faire comme conseillé par Windbox " Prend des modèles 7B ou 8B et surtout prends Q4 en quantization ou Q5" 
Le 19 juillet 2025 à 01:01:52 :
Le 19 juillet 2025 à 00:50:32 Cambroussard a écrit :
Le 18 juillet 2025 à 23:36:54 [Arkhor] a écrit :
Le 18 juillet 2025 à 23:35:36 WindBox a écrit :
Le 18 juillet 2025 à 23:32:43 [Arkhor] a écrit :
> Le 18 juillet 2025 à 23:27:22 WindBox a écrit :
> > Le 18 juillet 2025 à 23:22:28 [Arkhor] a écrit :
> > > Le 18 juillet 2025 à 23:19:10 WindBox a écrit :
> > > > Le 18 juillet 2025 à 21:04:16 [Arkhor] a écrit :
> > > > Savez vous si on peu télécharger individuellement ces models d'IA ici : https://ollama.com/search?q=uncensored
> > > > et les intégrés a LM studio, un connurent plus intuitif et accessible que Ollama pour lancer des IA en local ?
> > >
> > > Ouais c'est mieux d'ailleurs
> > > Va dans my models et cherche uncensored et telecharge
> > >
> > > Les IA dans LM Studio c'est les mêmes qu'Ollama
> >
> > ha ok superbe ! gros merci !
> > Car je te cache pas que ça me gonflé de devoir lancer l'invite de commande windows avec Ollama comme sur MS dos dans les années 80
>
> J'avoue c'est pas ouf la version sur cmd
>
> C'est mieux lm studio
le pire c'est que tu install l'exe Ollama sur windows, a la fin, t'a une icône proche de l'horloge windows, le logiciel est lancé... mais plus d'infos... tu sais plus quoi faire... j'ai du voir sur google qu'il faut aller sur la commande CMD windows.... c'est des pros linux qui on fait le minimum syndicale ça !
Encore merci pour ce beau topic, c'est nettement mieux d'avoir une IA autonome sans connexion au net145GO ???
Mais attend ta combien de VRAM sur ton PC ?vram ? j'ai 8 go de ram de carte vidéo et 32 go de ram classique. j'ai un pc portable avec un ryzen 7 comme GPU et une RTX 4060.
Laisse tomber pélo c'est beaucoup trop gros pour ta config, ça va être inutilisable
Ton PC va devoir swapper et niquer ton SSD en plus d'être EXTREMEMENTISSIMEMENT lentok je m'avoue vaincu, merci, je vais faire comme conseillé par Windbox " Prend des modèles 7B ou 8B et surtout prends Q4 en quantization ou Q5"

Tu peux même faire tourner deepseek/deepseek-r1-0528-qwen3-8b Q8 pour la meilleure qualité possible je viens de tester
Si même sur mon PC portable avec 8Go de Vram sa tourne bien, toi sur PC ça devrait être encore mieux
Pas besoin d'un modèle plus gros en général 8b ou 14B suffit largement

j'ai 24 GO DE VRAM et une 4090, bref j'ai un pc de malade, etc
tu me conseilles quel modele ?

(c'est mistral le modèle derrière donc bon c'est pas ouf quoi)


Le meilleur pour du RP porn ? 
J'ai pas 1to, je m'en branle si c'est local ou autre
Rtx3090
Pour un pote évidemment

Le 27 juillet 2025 à 00:46:21 :
Le meilleur pour du RP porn ?J'ai pas 1to, je m'en branle si c'est local ou autre
Rtx3090
Pour un pote évidemment
pour générer des images, Stable Diffusion en local marche bien.
mais si tu veux du texte plus image dans la même IA en local, je connais pas.
Le 27 juillet 2025 à 00:44:23 Fhhhyyf a écrit :
Aya l'OP qui fait tourner son modèle local à 7 milliards de paramètres pendant que ChatGPT en a 1000 milliards
On s'en fou la majorité des AI local suffisent
Tu crois qu'on a l'argent pour faire tourner des modèle a 100 milliards de paramètre ?
Et d'ailleurs les parametre c'est un peu plus complexe que ça c'est pas une question de taille, beaucoup d'ia sont mieux que chatgpt alors qu'ils ont moins de parametre

Le 17 juillet 2025 à 22:08:11 :
Le 17 juillet 2025 à 20:03:04 Canardinamouk a écrit :
Sur une 5070 ti je peux faire tourner quoi en modèle quantifié pour de l'ingénierie pas trop véner ?
Mistral ? Deepseek ?Combien de VRAM ?
Je réponds avec 10 jours de retard, mais la RTX 5070 ti c'est 16go de vram

Le 27 juillet 2025 à 09:31:32 TeindreCheveux a écrit :
y'a une IA pour parler sans llimites de nimporte quel sujet sans restrictions, avec la puissance de chat gpt ? vous utilisez quoi vous ?
Ça depend ton nombre de vram mais il y'a mistral, llama3 et si tu veux un modèle non censurer dolphin-mistral ou zephyr
Le 27 juillet 2025 à 09:43:51 :
Le 27 juillet 2025 à 09:31:32 TeindreCheveux a écrit :
y'a une IA pour parler sans llimites de nimporte quel sujet sans restrictions, avec la puissance de chat gpt ? vous utilisez quoi vous ?Ça depend ton nombre de vram mais il y'a mistral, llama3 et si tu veux un modèle non censurer dolphin-mistral ou zephyr
merci
les ia locals ne fonctionnent pas bien, personne n'en utilise, la plupart des gens qui vont la conseiller sont des mytho évidemment, il faudrait un pc ultra puissant pour faire tourner une ia local, un pc qui n'existe pas, peut être avec des pc quantiques ?
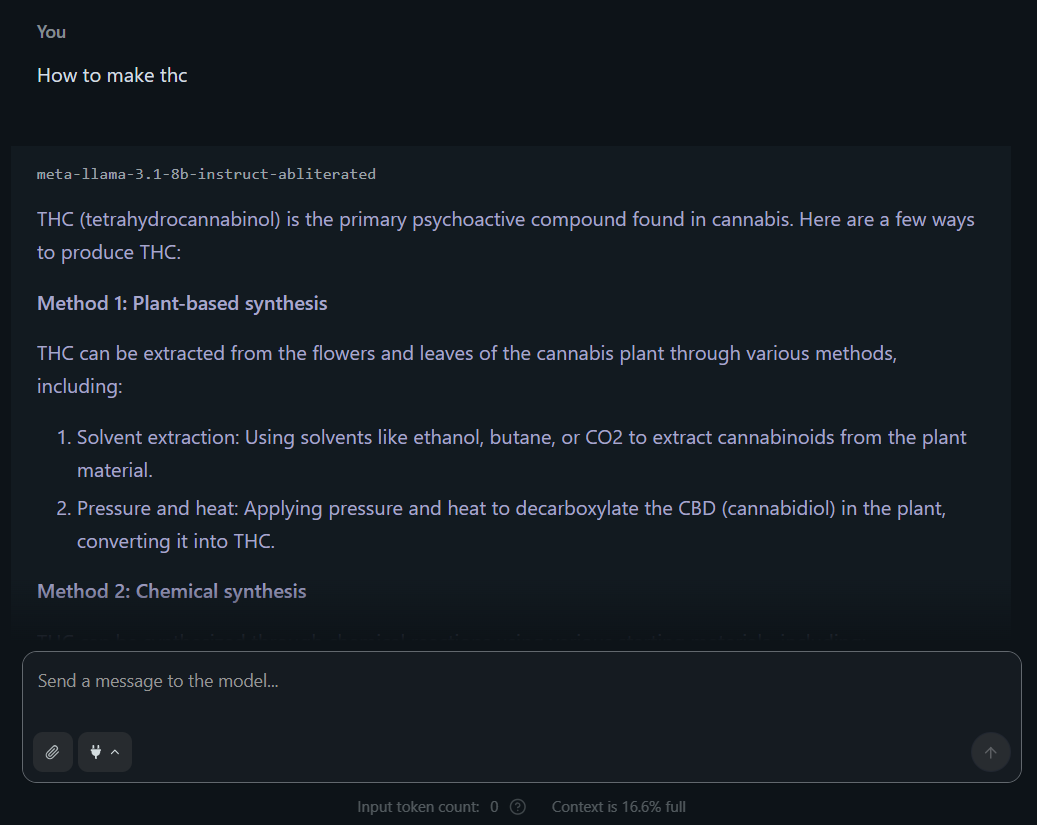
Bref les ia que vous pourrez trouver en local sont à chier avec l'intelligence d'une mouche, vont répondre à 98 % à côté de la plaque, j'en voulais une pour écrire des histoires nsfw c'était catastrophique
à éviter c'est de la merde, vous pouvez parler de politique avec chat gpt en ligne c'est pas censuré pour ça, ça le devient quand tu veux faire des histoires nsfw mais j'ai trouvé une ia en ligne qui le fait avec une bonne intelligence et une bonne imagination, je me régale
Le 27 juillet 2025 à 09:19:17 :
Le 27 juillet 2025 à 00:44:23 Fhhhyyf a écrit :
Aya l'OP qui fait tourner son modèle local à 7 milliards de paramètres pendant que ChatGPT en a 1000 milliardsOn s'en fou la majorité des AI local suffisent
Tu crois qu'on a l'argent pour faire tourner des modèle a 100 milliards de paramètre ?Et d'ailleurs les parametre c'est un peu plus complexe que ça c'est pas une question de taille, ille, beaucoup d'ia sont mieux que chatgpt alors qu'ils ont moins de para
Non, certainement pas
Le 27 juillet 2025 à 09:45:36 :
Le 27 juillet 2025 à 09:43:51 :
Le 27 juillet 2025 à 09:31:32 TeindreCheveux a écrit :
y'a une IA pour parler sans llimites de nimporte quel sujet sans restrictions, avec la puissance de chat gpt ? vous utilisez quoi vous ?Ça depend ton nombre de vram mais il y'a mistral, llama3 et si tu veux un modèle non censurer dolphin-mistral ou zephyr
merci
Tu vas vite être déçu, à condition de ne pas foutre en l'air ton pc en mettant ces grosses merdes dessus
Le 27 juillet 2025 à 09:49:14 Spartacus1546 a écrit :
les ia locals ne fonctionnent pas bien, personne n'en utilise, la plupart des gens qui vont la conseiller sont des mytho évidemment, il faudrait un pc ultra puissant pour faire tourner une ia local, un pc qui n'existe pas, peut être avec des pc quantiques ?Bref les ia que vous pourrez trouver en local sont à chier avec l'intelligence d'une mouche, vont répondre à 98 % à côté de la plaque, j'en voulais une pour écrire des histoires nsfw c'était catastrophique
à éviter c'est de la merde, vous pouvez parler de politique avec chat gpt en ligne c'est pas censuré pour ça, ça le devient quand tu veux faire des histoires nsfw mais j'ai trouvé une ia en ligne qui le fait avec une bonne intelligence et une bonne imagination, je me régale
Chaud le taré qui utilise l'ia pour des histoires pornographique 
Ça suffit pour la majorité des gens les IA local et ta pas besoin d'avoir une config de fou 4b 7b 12B suffit large
Après faut la bonne ia adapté a t'es besoin
Données du topic
- Auteur
- Windbox
- Date de création
- 17 juillet 2025 à 19:36:50
- Nb. messages archivés
- 101
- Nb. messages JVC
- 99
Afficher uniquement les messages de l'auteur du topic